
如何利用Python處理PDF
- Learn with Shin
- Oct 7, 2021
- 3 min read

今天要跟大家一起看一下工作或生活中都常常會接觸到的 -- PDF檔案。
PDF(全名Portable Document Format)的檔案中除了文字以外,可以有圖片,表格,甚至是動畫 -- 相當的賞心悅目。除了方便在網路上傳送,經常看到譬如說個人履歷表、銀行交易紀錄、公司財務報表、海報、廣告文案等等頃向會印出來的文件也都會使用PDF。
只是,美麗的東西往往都是帶刺的🌹。這些豐富的要素,使得處理PDF的資料具有相當程度的挑戰性。
大家有沒有曾經為了擷取PDF中的內容而氣到內傷的經驗?如果單純手動Copy & Paste裡面的內容,往往需要做不少後製的格式調整。
PDF某種程度是設計讓你無法輕易去更改,它就像一張畫布的概念。為了維持檔案的呈現樣貌,PDF中有許許多多複雜的要素存在,有興趣的話可以參考這裡。

接下來,我們來看看如何使用Python來幫助我們處理PDF檔案吧。
Python其實有不少處理PDF格式的Library,但是許多用法並不是那麼直覺。
因此,我們今天要來介紹的是個人覺得最簡單好用的 - pdfplumber。
首先安裝如下:
pip install pdfplumber==0.5.25擷取文字
第一個最常會用到的,就是擷取PDF中的文字部分。話不多說,就直接來看例子吧!
這裡是我們會用到的PDF檔案 (摘錄自Google的財務報表)
Code如下:
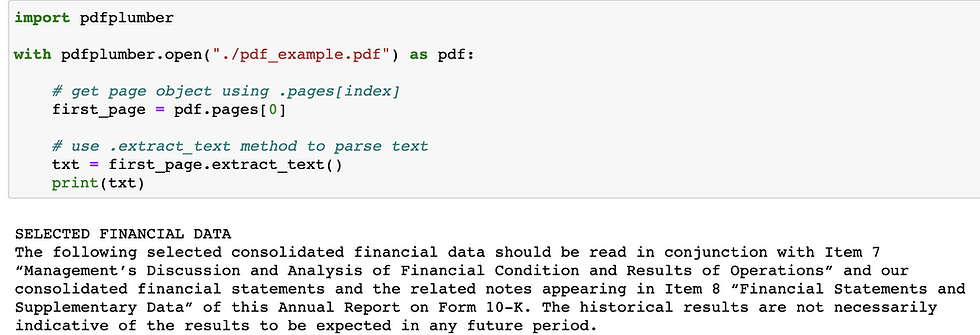
就這麼幾行code,我們就抓到了第一頁的文字了!!
利用pdfplumber.open這個函數,並指定檔案路徑來生成PDF的物件。
接著,利用.pages這個屬性,可以指定你要的頁數,在這裡我們指定要第一頁(pages[0])。
這個page本身也是一個物件,可以用page.extract_text來將文字內容擷取出來。
(這裡注意到,這個文字串的分行是完全按照PDF本身的長相,所以有時候你可能會覺得怎麼有些地方斷的怪怪的。因為PDF是一個固定的長相,不會根據你的閱覽畫面的尺寸去做調整。)
接下來,由於抓出來的text是一整個string,所以如果想要能更細部的去分析,我們可以簡單利用.split將它分行。"\n" 代表的是一個斷行的特殊字元。

這樣一來,如果我們有特定的資料需要去擷取,就容易處理多了。例如我可以去尋找每一行中含有 "shares"的句子:

擷取表格
再來,假設我們想要報表裡面的表格類型(table)的資料,

嗯~,當然我們用剛剛的.extract_text其實也可以抓到裡面的內容,畢竟都是text。不過這樣一來我們就得特別知道表格的位置及特徵,然後需要的話還得在自己建構一個表格。
其實,抓取PDF中的表格具有相當的挑戰性,因為PDF中並沒有真的有table的概念😟。
幸運的是,pdfplumber有提供.extract_table用來擷取內容中看起來像table的格式。
請看下面的例子:

抓是抓到了,只是看起來好樣有一些雜音,像是空白的string以及一堆None...
所以稍微做一點清理:

這樣看起來應該好多了!
接著根據你的需求也可以把它轉成DataFrame。

這裡要再重申一次,根據表格的呈現方式,往往擷取當中的資料不見得會很單純。例如說格子(cell)的高低不一樣、或是分隔線的有無,等等因素都可能導致無法成功抓取表格。
合併PDF
OK,接下來的Use case稍有不同,但是我覺得應該還蠻有用的,所以想跟大家也一起來看一下🙂。
假設我們有另外一個PDF檔案如下,
今天我想把這個檔案中的內容跟之前的PDF結合成一個PDF檔。怎麼樣可以利用Python來做到這一點呢??
對於這項任務(簡單來說就是把分別的PDF檔中的部分page擷取出來,做成一個新的PDF檔),我們會用到另外一個也很好用的Library,叫做PyPDF2。
安裝如下:
pip install PyPDF2==1.26.0話不多說,Code範例如下:

幾個重點:
利用PyPDF2的PdfFileReader,並提供檔案的路徑來讀取該PDF
範例中,我們單純要檔案的第一頁,利用pdf_reader.getPage(0)
透過PyPDF2的PdfFileWriter生成的物件,我們可以使用.addPage來加入剛剛我們拿到的page。
這裡我們用一個For loop,才不用寫兩次一樣的東西
將我們想要的pages都加入至PdfFileWriter物件後,接著就可以將它寫入檔案:

注意用到的模式是 "wb",因為我們寫入的是bytes,不是string喔。

這樣一來,我們就成功的將兩個不同的PDF檔的頁面結合成一個新的PDF檔了喔!😃
👏👏👏
結語
今天跟大家介紹了:
PDF的基本用途及構造
如何用pdfplumber來擷取PDF中的文字與表格內容
如何用PyPDF2來把分別的PDF檔中的部分page擷取出來,做成一個新的PDF檔
由於各種PDF的生成方式及呈現的複雜度,使得實作上處理PDF經常是一個具有相當挑戰性的任務。但是沒辦法,PDF是現今普遍會看到的資料來源的一種😢,因此當需要的時候,知道如何處理PDF將是相當重要。
今天到這裡,希望對大家有幫助喔~🙂



是不是中文不行?我按照範例不行找中文。